Introduction
Movie reviews can be classified as positive or negative. Here we are going to use Neural Networks to predict whther each review is positive or negative.
The training process is based on the IMDB dataset that contains the text of 50000 reviews.
After training, we will use the model to predict people’s sentiments about Avengers Endgame.
Data Exploration
import tensorflow as tf
from tensorflow import keras
import numpy as np
import pandas as pd
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
The dataset is evenly splited into training and testing set for learning process later.
print("Training entries: {}".format(len(train_data)))
print("Testing entries: {}".format(len(test_data)))
Training entries: 25000
Testing entries: 25000
Each review in the dataset has been prepocessed into a series of integers, where each integer represents a word. For example:
print(train_data[5])
[1, 778, 128, 74, 12, 630, 163, 15, 4, 1766, 7982, 1051, 2, 32, 85, 156, 45, 40, 148, 139, 121, 664, 665, 10, 10, 1361, 173, 4, 749, 2, 16, 3804, 8, 4, 226, 65, 12, 43, 127, 24, 2, 10, 10]
It is acctually a specific code for the review, and we can convert it back to sentences.
word_index = imdb.get_word_index()
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
decode_review(train_data[5])
"<START> begins better than it ends funny that the russian submarine crew <UNK> all other actors it's like those scenes where documentary shots br br spoiler part the message <UNK> was contrary to the whole story it just does not <UNK> br br"
Preprocessing
The reviews must be converted to tensors before fed into the neural networks. In other words, they must be the same length.
len(train_data[0]), len(train_data[5]), len(train_data[10])
(218, 43, 450)
Thus, we will use the pad_sequences function to standardize the lengths. Namely, we fill 0 into those less than 256 words and delete parts more than 256 words.
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
len(train_data[0]), len(train_data[5]), len(train_data[10])
(256, 256, 256)
print(train_data[5])
[ 1 778 128 74 12 630 163 15 4 1766 7982 1051 2 32
85 156 45 40 148 139 121 664 665 10 10 1361 173 4
749 2 16 3804 8 4 226 65 12 43 127 24 2 10
10 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
Modeling
# input shape is the vocabulary count used for the movie reviews (10,000 words)
vocab_size = 10000
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
model.summary()
WARNING:tensorflow:From C:\Users\wow97\Anaconda3\lib\site-packages\tensorflow\python\ops\resource_variable_ops.py:435: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160000
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 16) 272
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc'])
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=30,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
Train on 15000 samples, validate on 10000 samples
WARNING:tensorflow:From C:\Users\wow97\Anaconda3\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Epoch 1/30
15000/15000 [==============================] - 1s 88us/sample - loss: 0.6921 - acc: 0.5854 - val_loss: 0.6904 - val_acc: 0.7022
Epoch 2/30
15000/15000 [==============================] - 1s 44us/sample - loss: 0.6868 - acc: 0.7063 - val_loss: 0.6823 - val_acc: 0.7411
Epoch 3/30
15000/15000 [==============================] - 1s 44us/sample - loss: 0.6735 - acc: 0.7557 - val_loss: 0.6647 - val_acc: 0.7494
Epoch 4/30
15000/15000 [==============================] - 1s 43us/sample - loss: 0.6487 - acc: 0.7609 - val_loss: 0.6360 - val_acc: 0.7483
Epoch 5/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.6117 - acc: 0.7900 - val_loss: 0.5971 - val_acc: 0.7858
Epoch 6/30
15000/15000 [==============================] - 1s 44us/sample - loss: 0.5647 - acc: 0.8142 - val_loss: 0.5519 - val_acc: 0.8077
Epoch 7/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.5126 - acc: 0.8343 - val_loss: 0.5037 - val_acc: 0.8229
Epoch 8/30
15000/15000 [==============================] - 1s 47us/sample - loss: 0.4619 - acc: 0.8515 - val_loss: 0.4607 - val_acc: 0.8387
Epoch 9/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.4164 - acc: 0.8664 - val_loss: 0.4237 - val_acc: 0.8479
Epoch 10/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.3775 - acc: 0.8781 - val_loss: 0.3942 - val_acc: 0.8553
Epoch 11/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.3453 - acc: 0.8870 - val_loss: 0.3707 - val_acc: 0.8631
Epoch 12/30
15000/15000 [==============================] - 1s 46us/sample - loss: 0.3188 - acc: 0.8935 - val_loss: 0.3527 - val_acc: 0.8656
Epoch 13/30
15000/15000 [==============================] - 1s 48us/sample - loss: 0.2970 - acc: 0.8997 - val_loss: 0.3374 - val_acc: 0.8707
Epoch 14/30
15000/15000 [==============================] - 1s 48us/sample - loss: 0.2776 - acc: 0.9047 - val_loss: 0.3262 - val_acc: 0.8739
Epoch 15/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.2613 - acc: 0.9102 - val_loss: 0.3173 - val_acc: 0.8767
Epoch 16/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.2466 - acc: 0.9149 - val_loss: 0.3097 - val_acc: 0.8770
Epoch 17/30
15000/15000 [==============================] - 1s 46us/sample - loss: 0.2330 - acc: 0.9195 - val_loss: 0.3035 - val_acc: 0.8804
Epoch 18/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.2210 - acc: 0.9244 - val_loss: 0.2987 - val_acc: 0.8822
Epoch 19/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.2101 - acc: 0.9265 - val_loss: 0.2942 - val_acc: 0.8835
Epoch 20/30
15000/15000 [==============================] - 1s 46us/sample - loss: 0.2003 - acc: 0.9306 - val_loss: 0.2913 - val_acc: 0.8839
Epoch 21/30
15000/15000 [==============================] - 1s 46us/sample - loss: 0.1902 - acc: 0.9363 - val_loss: 0.2889 - val_acc: 0.8842
Epoch 22/30
15000/15000 [==============================] - 1s 52us/sample - loss: 0.1818 - acc: 0.9403 - val_loss: 0.2873 - val_acc: 0.8846
Epoch 23/30
15000/15000 [==============================] - 1s 50us/sample - loss: 0.1734 - acc: 0.9446 - val_loss: 0.2871 - val_acc: 0.8838
Epoch 24/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.1661 - acc: 0.9475 - val_loss: 0.2859 - val_acc: 0.8845
Epoch 25/30
15000/15000 [==============================] - 1s 48us/sample - loss: 0.1586 - acc: 0.9504 - val_loss: 0.2853 - val_acc: 0.8855
Epoch 26/30
15000/15000 [==============================] - 1s 46us/sample - loss: 0.1519 - acc: 0.9529 - val_loss: 0.2865 - val_acc: 0.8836
Epoch 27/30
15000/15000 [==============================] - 1s 45us/sample - loss: 0.1456 - acc: 0.9559 - val_loss: 0.2865 - val_acc: 0.8850
Epoch 28/30
15000/15000 [==============================] - 1s 48us/sample - loss: 0.1396 - acc: 0.9577 - val_loss: 0.2876 - val_acc: 0.8855
Epoch 29/30
15000/15000 [==============================] - 1s 46us/sample - loss: 0.1343 - acc: 0.9602 - val_loss: 0.2900 - val_acc: 0.8840
Epoch 30/30
15000/15000 [==============================] - 1s 48us/sample - loss: 0.1287 - acc: 0.9619 - val_loss: 0.2898 - val_acc: 0.8851
results = model.evaluate(test_data, test_labels)
print(results)
25000/25000 [==============================] - 1s 34us/sample - loss: 0.3067 - acc: 0.8758
[0.30674511832237245, 0.87576]
Further Testing

The performance of our model is not bad on the IMDB testing set. However, if the model can predict broader and more general samples, we believe it has stronger explanatory power. Therefore, we scrap reviews of Avengers: Endgame on the Rotten Tomatoes, which is another famous review-aggregation website for films and televisions, and use our model to predict people’s sentiments about the movie.
import requests
from bs4 import BeautifulSoup
def getReview(url):
df_list=[]
res= requests.get(url)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
for review in soup.select('.user_review'):
df_list.extend({review.text})
return df_list
url='https://www.rottentomatoes.com/m/avengers_endgame/reviews/?page={}&type=user&sort='
review_total=[]
for i in range(2,52):
review_url=url.format(i)
review_page=getReview(review_url)
review_total.extend(review_page)
len(review_total)
997
There are in total 997 reviews from audience on the website. Then, we need to tokenize the reviews, namely, breaking each sentence into a series of words.
from keras.preprocessing.text import text_to_word_sequence
token=[]
for i in range(0,len(review_total)):
word=review_total[i]
result = text_to_word_sequence(word)
token.append(result)
len(token)
997
Now, we need to map those words to the index in IMDB dataset for further analysis.
encode=[]
for i in range(0,len(review_total)):
r=([word_index[token[i]] if token[i] in word_index else 0 for token[i] in token[i]])
encode.append(r)
len(encode)
997
Since we set the vocabulary to be 10000 in the training process, transfromed index larger than 10000 should be deleted.
for lists in encode:
for j in lists:
if j > 10000:
lists.remove(j)
Similarly, length of each review needs to be standardized.
review_pad=keras.preprocessing.sequence.pad_sequences(encode,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
Result
import seaborn as sns
import matplotlib.pyplot as plt
clf=model.predict_classes(review_pad)
df = pd.DataFrame(clf, columns = ['sentiment'])
sns.countplot(x="sentiment", data=df)
plt.show()
per=np.count_nonzero(clf)/997
print('{:.2%}'.format(np.count_nonzero(clf)/997),'of people make positive reviews of Avengers: Endgame' )
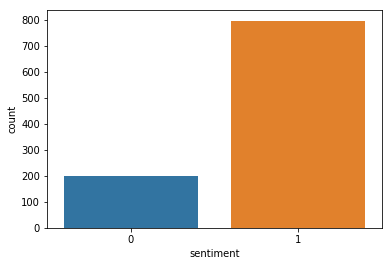
79.94% of people make positive reviews of Avengers: Endgame
It seems that most people like the movie, but how do we know it is true? As it is imposssible for me to label each review, here we use a crude way to demonstrate the accuracy, which is to randomly select 20 reviews in the sample and check whether it is correctly predicted.
import random
test=[]
for i in range(1,21):
n=random.randint(0,997)
review_rand=review_total[n]
review_predict=clf[n]
test.append({'review':review_rand,'prediction':review_predict})
df_test= pd.DataFrame(test, columns = ['review', 'prediction'])
pd.set_option('max_colwidth',500)
df_test
| review | prediction | |
|---|---|---|
| 0 | A befitting end to a total of 22 films spanning 11 years. This is a franchise like no other. A powerful and emotionally charged movie that sends messages of bravery, heroism, justice, family, and love. One should be moved by this flick even in a small way. It has all the elements of human emotions and therefore, this movie has a heart. CGI graphics were just insanely wonderful. Better to watch this in a Dolby Atmos surround sound system.For some, tissue paper or handkerchief would be requi... | [1] |
| 1 | 2 hour comedy and almost a hour fight. Totally boring and fkd up. | [0] |
| 2 | Maybe the snap should have taken out 75% of the characters so that the plot wasn't so disjointed and our heroes could have been more thoughtfully utilized (and their storylines developed better.) Endgame was a disappointment in so many ways. I'm so surprised by the positive reviews when so many beloved characters were treated with such a lack of care, the plot dragged along and had too many holes and the attempts to draw me in emotionally and comically completely failed to do so. I've been... | [0] |
| 3 | Satisfying ,Emotional,humor and best movie ever made in mcu love it ,you must go see it | [1] |
| 4 | Good but underwhelming considering the hype... | [1] |
| 5 | For the final film in the Infinity Saga, Marvel has brought forth a film that concludes 11 years worth of work and fan service. Though drawn out in certain scenes, Endgame dosent disappoint due to raw emotion and light hearted humor and ambition. | [1] |
| 6 | Great movie. Can't wait to see it again to dissect it. | [1] |
| 7 | Boring, slow, long, too much drama for an action film, you cant feel empathy when you see 45 films (stories) compressed in one 3-hours long movie | [0] |
| 8 | The timeline is a little bit confusing tbh. What i like about this End Game is that how RDJ character Tony Stark has grown since he saw the prophecy (which nobody taking it seriously esp Captain America that makes me hate him so much) and his encounter with Peter Parker (Spidey), that's when he determined to try the time travelling mission to get everybody back. It was heartbreaking to see Natasha and Tony died :'( When they were time traveled we got to see all of the previous Avengers sce... | [1] |
| 9 | This is how they used to make good movies. | [1] |
| 10 | Nothing in particular wrong. After all the hype i just found it disappointing and boring. It was hard to sit through 3 hours. | [0] |
| 11 | I watched endgame and knew that anything after would be as un original and lazy as that movie i was saddened that i was right | [0] |
| 12 | Over on hour too long. Very tedious movie. | [0] |
| 13 | Best. Superhero Movie. Ever! | [1] |
| 14 | Great movie great execution, well written script. It was great cinematic experience, it wasn't only �~action' movie it was about family, friends, love. The development of the characters were amazing, should be nominated as best pictures on oscar | [1] |
| 15 | very complicated, i like it.. must watch all of marvel movies to understand this Endgame | [1] |
| 16 | es la mejor película tiene drama, acción y comedia | [1] |
| 17 | it was ok, lots of filler | [1] |
| 18 | This movie is an epic masterpiece of cinema that does whatever it takes to make this the epic grand finale of 11 years of films | [1] |
| 19 | This was an amazing conclusion to The Avengers. #LoveYou3000 | [1] |
Let us manually check how many mistakes the model makes: No.8 is ambiguous and No.17 is mispredicted to positive review. The accuracy is roughly 90%, which is consistent with traning result above. Although the test design is simple, neural networks indeed has relatively strong power to predict sentiments of movie reviews.
Acknowledgement
The preprocessing and modeling are based on TensorFlow Tutorials